
Dlaczego Label Encoder może Ci zaszkodzić?

Na kursach Data Science uczą nas, że jak mamy dane jakościowe, to możemy sobie je zakodować wykorzystując Label Encoding (przypisanie kolejnych liczb naturalnych do wartości) albo One Hot Encoding (zrobienie ze zmiennej jakościowej kilku zmiennych, przyjmujących wartości 0 lub 1).
Pokażmy przykład, żeby nie brzmiało to zbyt abstrakcyjnie. Powiedzmy, że mamy zmienną przyjmującą 3 wartości: “Tak”, “Nie”, “Nie wiem”. Możemy ją zakodować za pomocą Label Encodera, przyjmując:
- 0 – Nie
- 1 – Nie wiem
- 2 – Tak
Możemy też wykorzystać One Hot Encoder, czyli zamienić tę jedną zmienną na 3, gdzie dwie z nich będą zerami, a jedna – odpowiadająca wybranej odpowiedzi będzie jedynką.
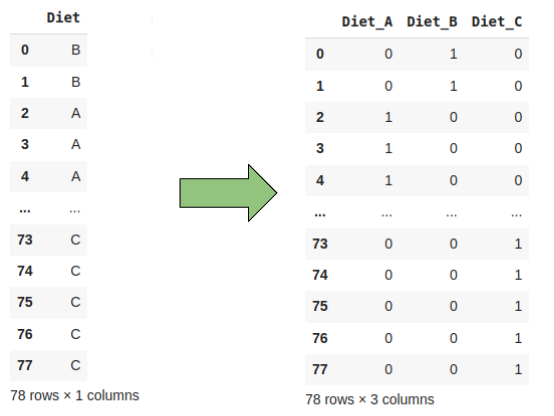
Jaki typ kodowania wybrać?
Za każdym razem gdy pracujemy z modelami uczenia maszynowego dane jakościowe musimy kodować. Modele działają na liczbach, a co za tym idzie dostarczenie im wartości “nie wiem” skutkowałoby brakiem możliwości wykonania obliczeń. Chyba nie ma jednoznacznej odpowiedzi co jest lepsze do stosowania. Wszystko zależy od modelu jaki zastosujemy, bo np. algorytmy oparte na drzewach decyzyjnych “nie odczuwają” różnicy związanej ze skalą danych, więc jeśli nasza kodowa zmienna ma 16 kategorii, to najwyższa wartość zakodowanej zmiennej równa 15 (bo indeksowanie zaczyna się od 0!) będzie ok, ale np. w sieci neuronowej nie powinniśmy tak robić. Z drugiej strony nie zawsze użycie label encodera będzie miało sens, ale o tym w dalszej części.
Regresja liniowa
Problem, który chcę omówić rozważymy na podstawie regresji liniowej. Zacznijmy zatem może od krótkiego wyjaśnienia czym jest regresja liniowa.
Regresja liniowa (zgodnie z tym co sugeruje nazwa) służy do modelowania zależności liniowej między danymi. Zmienną, którą przewidujemy nazywamy zmienną zależną lub zmienną objaśnianą. Natomiast zmienną czy też zmienne, które posłużą do wyznaczenia predykcji nazywamy niezależnymi lub objaśniającymi.
Dla prostego przykładu rozważmy sobie regresję liniową między dwoma zmiennymi – waga po stosowaniu diety przez 6 tygodni (zmienna objaśniana) i waga przed dietą (zmienna objaśniająca).
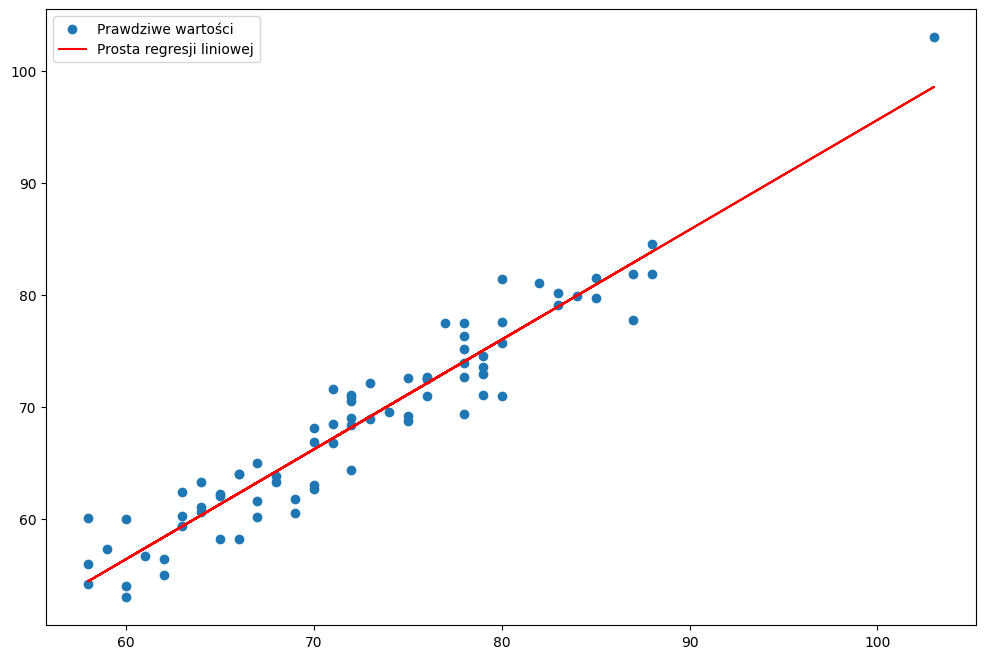
W przypadku, który widzimy na wykresie, prostą regresji można opisać bardzo prostym równaniem, które jest niczym innym jak funkcją liniową doskonale znaną nam ze szkoły:
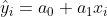
Oczywiście regresja liniowa może mieć wiele zmiennych niezależnych. Z każdą kolejną do równania będą dochodzić kolejne elementy dodawania. Dla przykładu przy 3 zmiennych niezależnych wzór na regresję będzie wyglądać następująco:
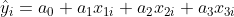
Trzymając się dalej tego samego przykładu powiedzmy, że rozważamy model regresji liniowej, gdzie do predykcji wykorzystujemy:
- x1 – wagę przed dietą
- x2 – wiek
- x3 – stosowana dieta (A, B lub C)
Oczywiście diety nie możemy tak po prostu wrzucić do modelu, bo jak tu niby przewidywać nową wagę, gdy w równaniu będziemy mieć litery? 🤔🤔🤔 Z pomocą przyjdzie nam tu kodowanie zmiennych!
I tu zaczyna się fun związany z label encoderem 🥳️🥳️🥳️🥳️
Skutki zastosowania label encodera w analizowanym przykładzie
Powiedziałam wcześniej, że nie zawsze użycie label encodera będzie miało sens i to jest dobry moment, żeby do tego wrócić. Zastanówmy się przez chwile co może pójsć nie tak, jeżeli w analizowanym przypadku użylibyśmy label encodera?
Powiedzmy, że zakodowaliśmy diety i mamy
- Dieta A – 0
- Dieta B – 1
- Dieta C – 2
Dla modelu to są konkretne liczby, a jak przystało na liczby, możemy stwierdzić, że zero to mniej niż 2. Co to oznacza dla modelu? Dokładnie tyle, że Dieta A to mniej niż Dieta B czy C. Oczywiście nie ma to najmniejszego sensu! Uwaga! Należy pamiętać, że nie każdy model będzie miał ten problem, np. W algorytmach drzewiastych użycie takiego kodowania NIE wpłynie na decyzję modelu. Mamy już przykład kiedy NIE UŻYWAĆ label encodera, zatem czas na przykład kiedy niby można, ale jednak nie można.
Kiedy label encoder ma sens, ale musimy zachować ostrożność?
Co jeśli zamiast diet mielibyśmy zmienną odpowiadającą za wielkość miasta w którym mieszka dana osoba? Dla uproszczenia przyjmijmy 4 opcje:
- Wieś
- Misto do 30 tys. mieszkańców
- Miasto do 100 tys. mieszkańców
- Miasto powyżej 100 tys. mieszkańców
Przy dietach powiedzieliśmy, że użycie label encodera sugerowałoby modelowi, że któraś dieta to “więcej” niż inna. Wielkość miasta jest zmienną na skali porządkowej (tu możesz doczytać nt. typów zmiennych), więc moglibyśmy przyjąć, że wieś to 0, miasto do 30 tys. to 1 itd. Dla rozważanego wcześniej modeli regresji liniowej byłaby to całkiem sensowna informacja, o ile zostanie zachowany porządek. Jest jednak małe “ale…”.
Jeżeli użyjemy label encodera z scikit-learn, to okaże się, że porządek NIE będzie zachowany. Encoder przypisuje zmiennym kategorycznym kolejne liczby naturalne zgodnie z porządkiem ASCII. W praktyce oznacza to mniej więcej tyle, że kodowanie będzie zgodne z alfabetem, czyli Wieś otrzyma największą liczbę. Tym samym model liniowy będzie uważał, że Wieś to więcej niż opcje z miastem, bo jest reprezentowane przez większą liczbę naturalną.
Co zrobić w takiej sytuacji?

Teoretycznie najprostszym wyjściem z sytuacji jest zastosowanie One Hot Encodera, ale co jeśli koniecznie zależy nam na poprawnym Label Encoderze? Istnieje jeszcze narzędzie (z jakiegoś powodu bardzo często pomijane na kursach) o nazwie Ordinal Encoder. Działa on podobnie jak Label Encoder, ale możemy narzucić mu pożądaną kolejność kodowania. Jest bardzo prosty w użyciu (szkoda tylko, że dokumentacja scikit-learn nie pokazuje jak narzucić tę kolejność, co przy pierwszej próbie użycia może prowadzić do szybkiego zniechęcenia 😞). Dlatego niżej podrzucam przykładowy kod pokazujący jak z tego kozystać na przykładzie zmiennej odnoszącej się do wielkości miasta.
import numpy as np
from sklearn.preprocessing import OrdinalEncoder
names = ['Wieś ',
'Misto do 30 tys. mieszkańców',
'Miasto do 100 tys. mieszkańców',
'Miasto powyżej 100 tys. mieszkańców']
x = np.random.choice(names, size=50, replace=True)
# Ordinal Encoder
oe = OrdinalEncoder(categories=[names])
oe.fit_transform(x.reshape(-1, 1))
oe_transformed = oe.transform(np.array(names).reshape(-1, 1))
print(dict(zip(names, oe_transformed.flatten())))
# rezultat
>>> {'Wieś ': 0.0, 'Misto do 30 tys. mieszkańców': 1.0, 'Miasto do 100 tys. mieszkańców': 2.0, 'Miasto powyżej 100 tys. mieszkańców': 3.0} Korzystając z Ordinal Encodera musimy pamiętać o dwóch rzeczach:
- Kolejność zmiennych dostarczamy jako lista (zawarta w liście) posortowana zgodnie z oczekiwaną kolejnością. Jest to związane z tym, że możemy więcej niż jedną zmienną kodować równocześnie.
- Dane dostarczamy w postaci macierzowej, nawet jeśli kodujemy tylko jedną zmienną. Wtedy należy dostarczyć macierz zawierającą tylko jedną kolumnę. Również jest to związane z możliwością kodowania więcej niż jednej zmiennej.
Podsumowanie
Napisałam ten post, ponieważ kiedyś “złapałam się” na zastosowaniu Label Encodera na zmiennej, która była na skali porządkowej. Uznałam wtedy, że przecież skoro ona jest porządkowa, to nie ma potrzeby użycia One Hot Encodera, a Ordinal Encodera jeszcze nie znałam. Chciałabym tym postem przypomnieć jak ważne jest dbanie nie tylko o jakość modeli, ale również o jakość preprocessingu (a właściwie to w szczególności preprocessingu). Zgodnie z najważniejszą zasadą Data Scientistów, której na studiach nauczył mnie jeden z moich ulubionych profesorów, “Garbage in – garbage out” preprocessing to najważniejsza część w tworzeniu modeli uczenia maszynowego. Pamiętajmy, aby preprocessing był przeprowadzany w bardzo przemyślany oraz poprawny sposób.