
Czy umiesz poprawnie stosować metryki w klasyfikacji?

Zacznę ten wpis od zadania Ci pytania: jakiej metryki używasz do sprawdzenia jakości swojego modelu klasyfikacji? Możesz zostawić odpowiedź w komentarzu 🙂 Mam nadzieję, że Twoja odpowiedź nie brzmiała accuracy (a jeśli już, to mam nadzieję, że wiesz kiedy NIE powinno to być accuracy).
Pisząc ten post mam wątpliwości, czy temat nie jest zbyt oczywisty, no ale z drugiej strony, jeżeli miałby on pomóc chociaż jednej osobie, to już będzie sukces!
Popularne metryki w klasyfikacji
Zacznijmy może od wyjaśnienia jakie mamy metryki do mierzenia skuteczności klasyfikacji i jak należy je interpretować. Na początek przedstawmy macierz pomyłek (przyda się do wyjeśnienia niektórych metryk) – w podejściu binarnym do klasyfikacji (rozważenie jedynie klasy pozytywnej i negatywnej) jest to macierz o wymiarze 2×2, gdzie na głownej przekątnej znajduje się liczba poprawnie zaklasyfikowanych obserwacji (zielone pola). W czerwonych polach znajduje się liczba obserwacji fałszywie zaklasyfikowanych jako pozytywne oraz fałszywie zaklasyfikowanych jako negatywne. Taką macierz można bez problemu rozszerzyć na dowolną liczbę klas. Wtedy macierz ma odpowiednio więcej kolumn oraz wierszy. Dla uproszczenia skupmy się jednak na przypadku binarnym.
Metryki:
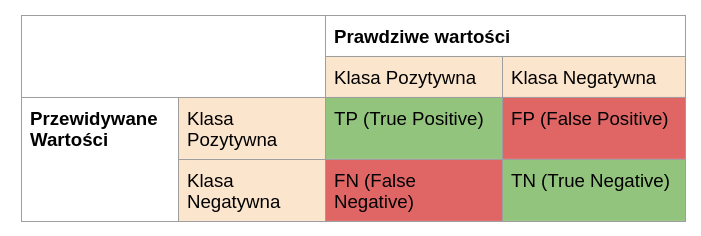
- Dokładność (ang. accuracy) – stosunek poprawnych predykcji do wszystkich, czyli jest to procent poprawnie zaklasyfikowanych obserwacji niezależnie od klasy.
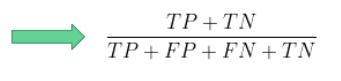
- Precyzja (ang. precision) – stosunek poprawnie zaklasyfikowanych jako pozytywne do wszystkich zaklasyfikowanych jako pozytywne, czyli mówi o tym jak często nasza predykcja będzie słuszna.

- Czułość (ang. recall) – stosunek poprawnie zaklasyfikowanych jako pozytywne do wszystkich pozytywnych, czyli mówi o tym jak często poprawnie rozpoznamy daną klasę.
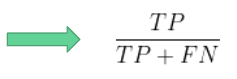
- F1-score – ważona średnia harmoniczna precyzji i czułości.

W przypadku dokładności zaznaczyłam, że wartość ta jest niezależna od klas. Wartość ta sama w sobie może być rozważana jako metryka skuteczności modelu. Pozostałe wymienione metryki są liczone “per klasa”, co oznacza, że jeżeli chcemy je wykorzystać do wyboru najlepszego modelu, to musimy np. uśrednić wartości z poszczególnych klas.
Wiemy już jakie mamy popularne metryki i jak należy je interpretowac, to teraz czas na decyzję z czego skorzystać. Noooo i tu musze powiedzieć chyba ulubiony tekst data Scientist’ów “to zależy“. Po pierwsze zastanów się nad tym jak wygląda proporcja w Twoich klasach. Jeżeli w jednej klasie masz znacznie więcej wartości niż w drugiej, to ta Klasa będzie miała większy wpływ na wartość accuracy.
Przytoczę teraz mój ulubiony przykład. Powiedzmy, że chcesz przewidywać, że dana osoba choruje na pewną bardzo rzadką chorobę. Choroba jest na tyle rzadka, że w Twoim zbiorze jest 10 razy mniej obserwacji z klasy pozytywnej. Oczywiście w takiej sytuacji można się posilać różnymi metodami sztucznego powiększania zbiorów czy próbować stosować wykrywanie outlierow zamiast klasycznych metod klasyfikacji, ale o tym innym razem. Skupmy się na sytuacji, gdy koniecznie chcemy / musimy iść w klasyfikację. W takiej sytuacji przede wszystkim NIE MOZEMY stosować accuracy jako wyznacznika skuteczności modelu . Dlaczego tak jest? Dla jasności przykładu przyjmijmy, że w klasie osób zdrowych mamy 990 osób a w klasie chorych 10. Nasz model może zawsze próbować przewidywać, że osoba jest zdrowa i mieć 99% skuteczności. Oczywiście takie 99% skuteczności jest absolutnie nic nie warte 😅😅
No to jeśli nie accuracy to co?
Tutaj znowu możliwości mamy bardzo dużo, wszystko zależy od Twoich danych. Postaram się teraz omówić wszystkie przypadki pokazując zarówno kiedy warto korzystać z poszczególnych metryk jak i potencjalne problemy za nimi idące.

A gdyby tak użyć średni recall albo recall grupy pozytywnej?
I tak I nie. Recall wskaże nam jak dużo obserwacji z danej klasy zostało do niej przypisane. Niby spoko, bo od razu mamy informacje jak skutecznie przewidujemy, że osoba jest chora gdy ona rzeczywiście jest chora. Co zatem nie działa w tym podejściu? Opcja 1, czyli recall klasy pozytywnej – znowu możemy stanąć przed sytuacją, że model wszystkich przypisze do jednej klasy – tym razem pozytywnej i ponownie mamy bezużyteczny model. To może średnia? Przecież jakby przypisało wszystkich do jednej grupy, to Klasa Negatywna otrzymałaby recall na poziomie zero, więc zepsułoby to średnią. Oczywiście podążając za średnią znacząco zmniejszamy szanse otrzymania modelu skupionego na jednej grupie, ale wchodzi tu inne zagrożenie. Jeżeli mamy tak znaczącą różnice liczebności jak przytoczona wcześniej, czyli 990 vs 10, to model mógłby przewidzieć w 90 przypadkach osób zdrowych, że chorują a recall klasy negatywnej byłby bardzo wysoki bo około 90%. Jednak jesteśmy wtedy w sytuacji, że jeżeli model przewiduje ze jesteś chory_a, to masz jedynie 10% szans na to że rzeczywiście jesteś chory_a. Czy to źle? Ehhhh i znowu muszę użyć tych słów… to zalezy 😅😅
Tym razem wchodzi tu ogromna liczba czynników mająca znaczenie. Przede wszystkim znaczenie będzie mieć powaga choroby. Gdyby taki model miał wspomagać wstępną diagnozę poważnej choroby, to ta proporcja 9/10 osób jest jednak zdrowych prawdopodobnie będzie w porządku (o ile dotychczas na dalsze badanie było kierowanych więcej zdrowych lub mniej chorych osób). Jeśli z drugiej strony miałby to być np. Test diagnozujący Covid w czasach pandemii, to trochę nie wyobrażam sobie, że na 10 osób wysłanych na kwarantannę 9 jest zdrowych. Jak widać “to zależy” jest w tym przypadku bardzo dobrym określeniem.
To może warto sugerować się precyzją?
Precyzja jest to wskaźnik, który powie nam o “wydajności modelu” w takim sensie, że dowiemy się ile % osób zaklasyfikowanych jako chorych jest rzeczywiście chorych. I tu wracamy do analogicznej sytuacji jaka była przy recallu. Tym razem możemy mieć sytuację, że model jest na tyle ostrożny, że spośród 10 chorych tylko jedną osobę zaklasyfikował jako chorą, ale dzięki temu żadnej osobie zdrowej nie zasugerował choroby. W takiej sytuacji precyzja dla osób chorych wynosi 100%, ale jednocześnie recall będzie bardzo niski. Łatwo zauważyć, że recall i precyzja są bardzo mocno powiązane ze sobą. Czy możemy w takim razie znaleźć sposób który połączy w sobie informację płynącą z obu tych metryk? Tak i w ten sposób dochodzimy do omówienia f1-score….
F1-score lekarstwem na wszystko
F1-score jest najlepszą metryką skuteczności modelu w sytuacji, gdy w klasyfikacji nie jest zachowana proporcja klas. Im wyższa wartość zarówno precyzji jak i recall jednocześnie, tym wyższa wartość F1-score. Z drugiej strony niska wartość którejś spośród wymienionych wcześniej metryk skutkuje obniżeniem się F1-score. Tym samym opisywane wcześniej sytuacje, gdzie recall/precyzja są idealne, ale druga z nich bardzo niska przełoży się na niską wartość F1-score. Jeżeli będziemy sugerować się średnią wartością F1-score, to prawdopodobnie wybierzemy optymalny klasyfikator. Oczywiście w sytuacji, gdy klasy są równoliczne (albo chociaż liczba obserwacji na klasę jest podobna w każdej klasie), to dokładność (accuracy) będzie również dobrą metryką skuteczności. Niestety, bardzo rzadko można spotkać się z tak idealną sytuacją i to jednak F1-score powinien (w większości sytuacji) służyć nam jako podstawowa metryka do oceny skuteczności modelu.
Podsumowanie
Każda metryka niesie pewną informację, która w poszczególnych przypadkach może być nawet jedyną której poszukujemy. Wszystko zależy od problemu, powagi sytuacji i tego na ile możemy sobie pozwolić na uzyskanie wyników będących False-positive czy False-Negative. Każdą sytuację należy rozważać indywidualnie. Jeżeli jednak szukamy po prostu metryki, która zawsze się sprawdzi, to F1-score jest metryką, której wartość pozwala znaleźć złoty środek dla pozostałych metryk.
PS. W tym podsumowaniu pominięta została metryka AUC i idąca z nią w parze krzywa ROC. Uważam, że zasługują one na nieco dłuższe omówienie. Jak tylko taki wpis się pojawi, to podrzucę tu linka. Tymczasem daj znać w komentarzu czy był*ś swiadom* potencjalnych problemów omówionych w artykule.